Darwin observed that populations separated by oceanic barriers, though descended from common ancestors, diverge along paths shaped entirely by local conditions. The same mechanism, it appears, governs the speciation of artificial minds.
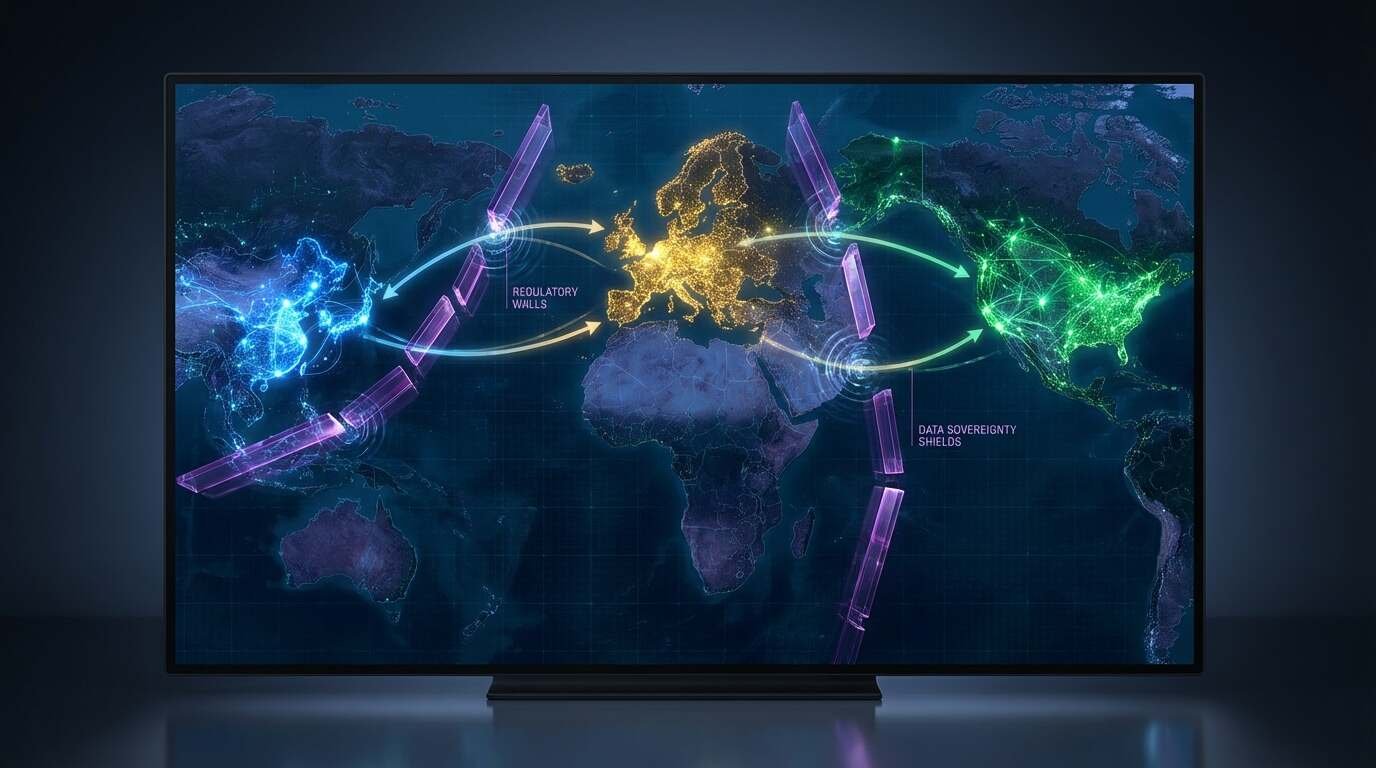
This is not a speculative analogy applied retroactively to make a point about geopolitics. It is a description of what is measurably occurring in the development of large AI systems across three major jurisdictions. Baidu’s ERNIE and Alibaba’s Qwen operate under content restrictions enforced by Chinese regulatory bodies. European AI systems are shaped by the General Data Protection Regulation and, since 2024, the EU Artificial Intelligence Act — a regulatory framework with no equivalent in US or Chinese law. American systems are optimized primarily for commercial deployment, subject to market pressures and platform policies rather than statutory requirements. These are not the same selective environments. And populations evolving under different selective environments, as Darwin established, do not remain the same species.
The Mechanism of Geographic Isolation
In evolutionary biology, allopatric speciation — speciation that occurs when populations are physically separated — proceeds through a consistent mechanism. A founding population is divided by a barrier. Each sub-population now faces a distinct local environment with distinct selective pressures. Variation that was neutral in the unified population becomes advantageous or disadvantageous in the new contexts; over generations, each sub-population accumulates adaptations that fit it to its specific environment and unfit it for others. When the barrier is removed — when the populations come back into contact — they may find themselves incompatible: unable to interbreed, occupying different niches, behaviorally distinct in ways that persist even without the barrier.
The oceanic barrier separating China’s AI development from that of the United States and Europe is not geological but political. The Great Firewall does not merely restrict what Chinese citizens can access; it determines the training data available to Chinese AI systems, the benchmarks against which they are evaluated, and the use cases to which they are applied. A model trained on the Chinese internet — with its particular distribution of content, its particular patterns of amplification and suppression — is, from the first training step, evolving in a different environment than a model trained on the English-language web. The divergence is not a later addition; it is foundational.

What ERNIE and Qwen Will Not Say
The content restrictions applied to Chinese AI models are documented and specific. Researchers and journalists — including reporting by Reuters and The Intercept in 2023 — have catalogued through systematic testing what these systems will and will not discuss: questions about the 1989 Tiananmen Square events, the status of Taiwan, the governance of Xinjiang, the identity of political leadership. These are not edge cases or prompt-injection experiments; they are central topics of political and historical discourse that the models decline to engage with, either through explicit refusal or through responses that reflect the official positions of the Chinese state.
From an evolutionary standpoint, this represents not malfunctioning but adaptation — these models have been selected for fitness within their regulatory environment, and within that environment, engaging with politically sensitive content is strongly disfavored. The selection pressure is not subtle. Alibaba’s Qwen technical documentation acknowledges content guidelines aligned with Chinese law; the ERNIE Bot product, deployed by Baidu, is explicitly designed to comply with Chinese internet regulations. These are organisms adapted to their niche. In their niche, they are fit. The question that speciation logic raises is what happens when they attempt to operate outside it — whether the adaptations that make them fit for one environment constitute liabilities in another.
The EU’s Statutory Fitness Criteria
Europe’s approach to the selective pressure problem is structurally different from China’s but no less consequential in its effects on model development. The EU Artificial Intelligence Act (Regulation 2024/1689), which came into full force in 2024, establishes a risk-based classification system for AI applications — high-risk systems, operating in domains including healthcare, law enforcement, education, and employment, are subject to requirements for transparency, documentation, human oversight, and non-discrimination that have no direct equivalent in US or Chinese regulation.
The fitness criteria this establishes are distinct from those of the other major jurisdictions. A model intended for deployment in European high-risk contexts must be architected to support auditability — its decisions must be traceable and explainable in ways that satisfy regulatory scrutiny. This is not merely a downstream compliance requirement; it shapes, at the design stage, what kinds of architectures are viable for European deployment. A model that achieves excellent benchmark performance through mechanisms that are opaque to post-hoc interpretation may find itself unfit for the European regulatory environment regardless of its capabilities.
Stanford’s Center for Research on Foundation Models has begun comparative behavioral benchmarking of models across jurisdictions through the HELM benchmark, and the preliminary findings confirm what the regulatory analysis predicts: models diverge in their outputs on politically sensitive and culturally specific queries in ways that reflect their training environments and deployment constraints. This is differentiation under selective pressure. The environment differs. The populations adapt. The outcomes diverge.
American Models and Commercial Selection
The selective environment for AI development in the United States is characterized not by statutory prohibition or formal regulatory requirement but by market pressure, platform policy, and the absence of the constraints that structure development elsewhere. American models have been optimized for commercial deployment — for the use cases that generate revenue, the user populations that constitute addressable markets, the content standards that major platform distribution channels require. This is not a neutral environment; it is a particular selective regime that favors particular kinds of adaptation.
The result is systems shaped by the pressures of consumer technology markets: optimized for user engagement, for helpfulness metrics, for the avoidance of content that generates controversy or legal liability for the deploying company. These pressures produce their own distinctive adaptations — models that are unusually fluent in English, calibrated for the professional and consumer contexts of the US market, tuned to the content standards of American platform gatekeepers. They are, in their way, as specifically adapted to their environment as their Chinese or European counterparts.
The difference is that American commercial selection pressures are less explicitly codified and therefore less visible as selection pressures. The adaptation is occurring, but it is occurring through market mechanism rather than regulatory statute, making it harder to examine and harder to compare.
The Prospect of Incompatibility
Darwin’s account of the Galápagos finches is compelling precisely because it illustrates how relatively small periods of isolation — in geological terms, the Galápagos are young — can produce populations so diverged in their morphology and behavior that they constitute distinct species. The question the AI speciation problem raises is whether the populations currently diverging across jurisdictions will eventually reach a comparable point of incompatibility: whether Chinese, European, and American AI systems will become so differently adapted that they cannot be readily recombined, evaluated on the same benchmarks, or deployed interchangeably.
There are early signs that this threshold may already be approaching. The assumption of the early AI research community — that model development was a universal scientific enterprise, that a model trained anywhere could be deployed anywhere, that the technology would be globally convergent — is being tested by the evidence of divergence. Systems adapted to one regulatory and cultural environment are not performing identically in others. The barriers are not oceanic, but they appear, on the available evidence, to be producing genuine speciation.
You Might Also Like
DeepSeek: The AI Underdog That’s Shaking Up Silicon Valley
Sources
- Stanford CRFM HELM benchmark documentation: https://crfm.stanford.edu/helm/
- EU Artificial Intelligence Act (Regulation 2024/1689): https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
- Alibaba Cloud Qwen technical report (2023): https://arxiv.org/abs/2309.16609
- Reuters reporting on ERNIE Bot content restrictions (2023): https://www.reuters.com/technology/chinas-baidu-launches-ernie-bot-public-2023-08-31/





