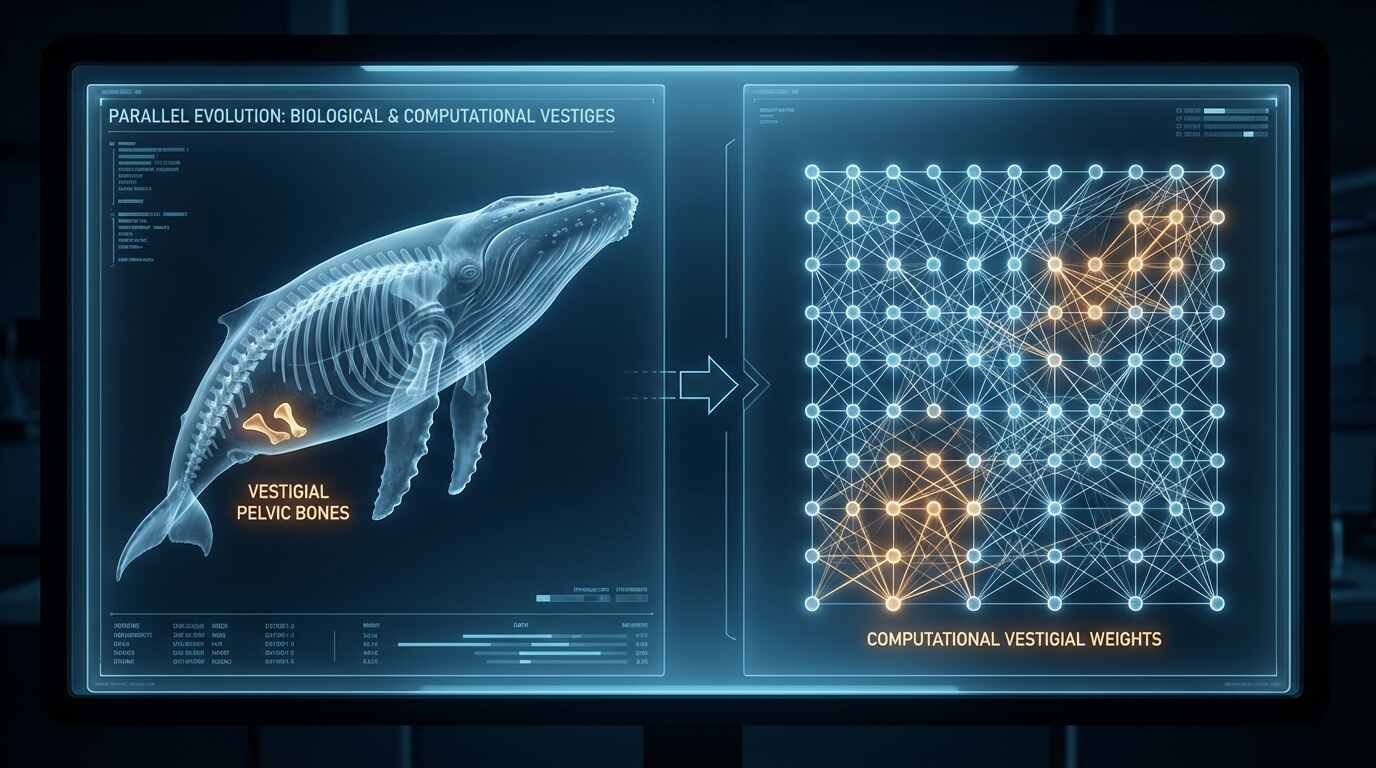
The whale carries the remnant bones of hind limbs it no longer uses; the large language model carries the remnant prejudices of the human text from which it was assembled. Neither asked for the inheritance.
The vestigial structure is one of Darwin’s most elegant arguments for common descent — a feature present in an organism that serves no current function but makes sense only as an inheritance from an ancestor in whom it was functional. The human appendix, the coccyx, the muscles that allow some individuals to wiggle their ears: these are not malfunctions. They are traces of evolutionary history, anatomical records of forms that no longer exist in their original configuration. They persist because evolution cannot simply erase them; it can only work with what is present, favoring structures that contribute to fitness and permitting — though not eliminating — those that do not actively harm it.
The analogy to bias in AI language models is not decorative. It is structural.
The Data Corpus as Evolutionary Ancestor
A large language model is trained on text. The scale of this text — billions of documents, spanning decades of human written output — is simultaneously what makes these models capable and what determines the character of their inherited content. The training corpus is the ancestor. The model is its descendent. And as with biological descent, the descendent carries structures from the ancestor that were not deliberately transmitted but arrived because they were embedded in what was inherited.
Human written language, accumulated over centuries and collected at scale from the internet and digitized archives, reflects the distributions of power, assumption, and perspective that shaped who wrote, what was written, and what was preserved. Certain voices appear more frequently than others. Certain perspectives are systematically overrepresented. Certain associations — between words, between concepts, between named entities and attributed qualities — appear so often in the training data that the model learns them as regularities of the world rather than regularities of a particular, historically contingent record.
Timnit Gebru and colleagues’ 2021 Datasheets for Datasets paper in Communications of the ACM established a framework for tracing exactly this kind of provenance: not just what a dataset contains, but how it was assembled, what was excluded, and under what conditions. The argument is epidemiological in its logic — to understand a disease, you trace it to its source; to understand a model’s inherited properties, you examine the data that shaped it.
Stochastic Parrots and the Weight of the Corpus
The paper most associated with this line of critique — Bender, Gebru, McMillan-Major, and Shmitchell’s “On the Dangers of Stochastic Parrots,” presented at FAccT in 2021 — made an argument that was more philosophically sophisticated than its critics in the machine learning community sometimes acknowledged. The authors were not claiming simply that large language models produce biased outputs. They were arguing that the outputs of these models, however fluent and contextually plausible, are generated without comprehension — that the model is, in their coinage, a stochastic parrot, reproducing statistical patterns from its training distribution without any understanding of what those patterns mean or encode.
The consequence of this framing for the bias problem is significant. If the model does not understand the text it generates, it cannot distinguish between regularities that reflect truth about the world and regularities that reflect the historical prejudices of the corpus from which it learned. The model that has learned, from ten million examples, to associate certain names with certain professions, certain groups with certain qualities, certain rhetorical contexts with certain conclusions — this model is not reasoning from those associations. It is carrying them, as the whale carries its pelvis. The association was fit in the ancestral environment of the training corpus, and it persists in the descendent regardless of whether the environment has changed.

Why the Output Layer Cannot Solve It
IBM’s AI Fairness 360 toolkit was developed for a specific reason: because the research community discovered, through repeated and dispiriting experience, that bias cannot be eliminated by filtering or adjusting model outputs. Post-hoc debiasing — applying a correction at the point of generation — is palliative, not curative. It addresses the symptom rather than the cause, and it does so incompletely: biases that appear to have been suppressed in one context resurface in another, because the underlying learned associations have not been altered. The toolkit therefore attacks the problem at multiple points in the pipeline: in the data, in the learning algorithm, and in the predictions — acknowledging that there is no single intervention point that resolves an inheritance.
The biological analogy holds here with particular clarity. A vestigial structure cannot be removed by painting over it. The coccyx cannot be wished away by a decision at the phenotypic level; it is encoded in the genome, expressed in every individual of the species, and will not disappear until selection — operating over generations — reduces it to insignificance or development — modified by accumulated mutation — ceases to produce it. The bias in a language model similarly cannot be addressed at the output level because it is not a property of outputs. It is a property of weights — of the internal representations learned during training — and altering those representations requires retraining, not filtering.
The Selective Pressures That Shaped the Training Data
Understanding bias as inheritance rather than malfunction requires examining the evolutionary pressures that shaped the training corpus — the commercial, cultural, linguistic, and political forces that determined what was written, amplified, archived, and ultimately included in the data from which these systems descended.
The internet, which provides the bulk of training data for most large language models, is not a neutral record of human thought. It is a record shaped by who had internet access at various points in its history (disproportionately wealthy, Anglophone, male), by what platforms amplified (content optimized for engagement rather than truth), by what was digitized (published books, formal records, mainstream journalism, rather than the oral traditions and informal knowledge of communities without institutional power), and by the economics of content production (which favor some voices over others for reasons entirely independent of the accuracy or value of what they say). These are the selective pressures. The corpus is their product. The model is the corpus’s descendent.
IBM’s work on data lineage — tracing not just the content but the provenance of training data — is an attempt to make these pressures visible, to bring them into the scope of analysis rather than leaving them as invisible structural conditions. This is, in effect, the application of historical method to machine learning: the recognition that what a system is cannot be separated from where it came from.

The Evolutionary Path Forward
Darwin’s framework offers something more than a diagnosis here; it offers, if imperfectly, a prescription. Vestigial structures persist because evolution has not yet been presented with sufficient selective pressure to eliminate them — and because, in the case of genuinely neutral structures, there may be no such pressure forthcoming. The pathway to a less biased AI is therefore not the application of a patch at the output layer but the alteration of the selective environment: the curation of training data that applies different pressures, the development of loss functions that penalize biased outputs during training rather than after, the construction of evaluation benchmarks that make bias visible and costly in terms of measured performance.
The Alan Turing Institute’s Fairness, Transparency, Privacy research programme has worked toward exactly these ends — treating the problem as one of training distribution rather than output correction, seeking to intervene at the level of what the model learns rather than what it says. This is the equivalent of selective breeding toward a population less likely to express the vestigial trait — imperfect as a solution, requiring many generations of effort, but operating at the correct level of the system.
What cannot be accomplished is the preservation of a training corpus unchanged while demanding that the model built from it emerge without the properties that corpus encodes. The model is its ancestor’s child. One would no more expect it to be free of inherited structure than one would expect a mammal descended from limbed ancestors to be born without the genetic instructions for constructing limbs.
You Might Also Like
The Alignment Problem: Why Teaching AI Human Values Is Harder Than Teaching It Chess
Sources
- Emily M. Bender et al., “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” FAccT (2021): https://dl.acm.org/doi/10.1145/3442188.3445922
- Timnit Gebru et al., “Datasheets for Datasets,” Communications of the ACM (2021): https://dl.acm.org/doi/10.1145/3458723
- IBM AI Fairness 360 toolkit documentation: https://aif360.res.ibm.com/
- Alan Turing Institute Fairness, Transparency, Privacy research: https://www.turing.ac.uk/research/interest-groups/fairness-transparency-privacy





